Post summary: How to colour your log files for better perception under Linux.
I’m far away from being a Linux guru and honestly, I like it that way. In order to be effective as a QA, you need to have minimal knowledge how to do certain things under Linux. This post is devoted to working with logs.
Chaining commands
Linux offers a possibility to combine several commands by chaining them. In the current post, I will just one of them, the PIPE (I) operator. By using it the output of one command is used as input for other.
I would strongly recommend reading following post if you are interested in chaining Linux commands: 10 Useful Chaining Operators in Linux with Practical Examples.
Useful commands
Commands below are one I use on a daily basis when working with logs. I will show basic usage, if you need more detail on certain command then you can type: man <command> e.g. man cat in Linux console and it will display you more information.
grep
It is used to search in text files or print lines matching some pattern. Usage is: grep text filename.log. If text contains spaces it should be wrapped around single quote (‘) or double quote (“). If text contains a single quote, then you have to wrap it around with double quote and vice versa.
cat
Prints file content to standard out put. Usage is: cat filename.log. You can concatenate several files: cat file1.log file2.log. Drawback using this command is when you have large files. It combines very well with grep to search output of the file: cat filename.log | grep text.
zcat
Prints content of a zipped file. Usage: zcat filename.gz. Combines with grep: zcat filename.gz | grep text.
tail
Prints last 10 lines from a file. Usage: tail filename.log. Most valuable tail usage is with -f option: tail -f filename.log. This monitor file in real time and outputs all new text appended to the file. You can also monitor several files: tail -f file1.log file2.log.
less
Used for paging through a file. It shows one page and with arrow key up and down you can scroll through the file. Usage: less filename.txt. In order to exit just type q. Valuable with this command is that you can type a search term /text and then with n go to next appearance and with N go to previous.
Colours
Commands above are nice, but using colours aid for a much better perception of information in the files. In order to use colours perl -pe command will be used as a chained command to colour the output of commands described above. Syntax is: perl -pe ‘s/^.*INFO.*$/\e[0;36;40m$&\e[0m/g’. It is quite a complex expression and I will try to explain it in details.
Match text to be highlighted
^.*INFO.*$ is a regular expression that matches a text to be highlighted. Character ^ means from the beginning of the string or line, character $ means to end of string or line. Group .* matches any character. So this regular expression means inspect every string or line and match those that contain INFO.
Text effects
\e[0;36;40m is the colouring part of the expression. 0 is value for ANSI escape code. Possible values for escape code are shown in the table below. Note that not all of them are supported by all OS.
| Code | Effect |
| 0 | Reset / Normal |
| 1 | Bold or increased intensity |
| 2 | Faint (decreased intensity) |
| 3 | Italic: on |
| 4 | Underline: Single |
| 5 | Blink: Slow |
| 6 | Blink: Rapid |
| 7 | Image: Negative |
| 8 | Conceal |
| 9 | Crossed-out |
More codes can be found in ANSI escape code wiki.
Text colour
36 from \e[0;36;40m is colour code of text. Colour depends and is different based on escape code. Possible combinations of escape and colour codes are:
| Code | Colour | Code | Colour |
| 0;30 | Black | 1;30 | Dark Grey |
| 0;31 | Red | 1;31 | Light Red |
| 0;32 | Green | 1;32 | Lime |
| 0;33 | Dark Yellow | 1;33 | Yellow |
| 0;34 | Blue | 1;34 | Light Blue |
| 0;35 | Purple | 1;35 | Magenta |
| 0;36 | Dark Cyan | 1;36 | Cyan |
| 0;37 | Light Grey | 1;37 | White |
Background colour
40m from \e[0;36;40m is colour code of background. Background colours are:
| Code | Colour |
| 40m | Black |
| 41m | Red |
| 42m | Green |
| 43m | Yellow |
| 44m | Blue |
| 45m | Purple |
| 46m | Cyan |
| 47m | Light Grey |
Sample colour scheme for logs
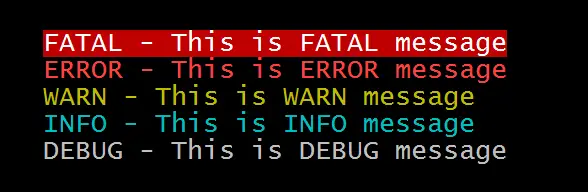
One possible colour scheme I like is: cat application.log | perl -pe ‘s/^.*FATAL.*$/\e[1;37;41m$&\e[0m/g; s/^.*ERROR.*$/\e[1;31;40m$&\e[0m/g; s/^.*WARN.*$/\e[0;33;40m$&\e[0m/g; s/^.*INFO.*$/\e[0;36;40m$&\e[0m/g; s/^.*DEBUG.*$/\e[0;37;40m$&\e[0m/g’ which will produce following output:
Conclusion
Having coloured logs makes it much easier to investigate logs. Linux provides tooling for better visualisation so it is good to take advantage of those.