Post summary: Some details on Gatling results report.
Current post is part of Performance testing with Gatling series in which Gatling performance testing tool is explained in details.
If you have followed the Gatling series so far you should know how to record a simulation, what simulation consists of, how to create Maven project and make code well structured and maintainable. Now is the time to run that code and see the results.
Gatling global information
Gatling has a pretty cool looking report. It shows global information about simulation as long as more detailed information for each request or request group. This is how the global information looks like:
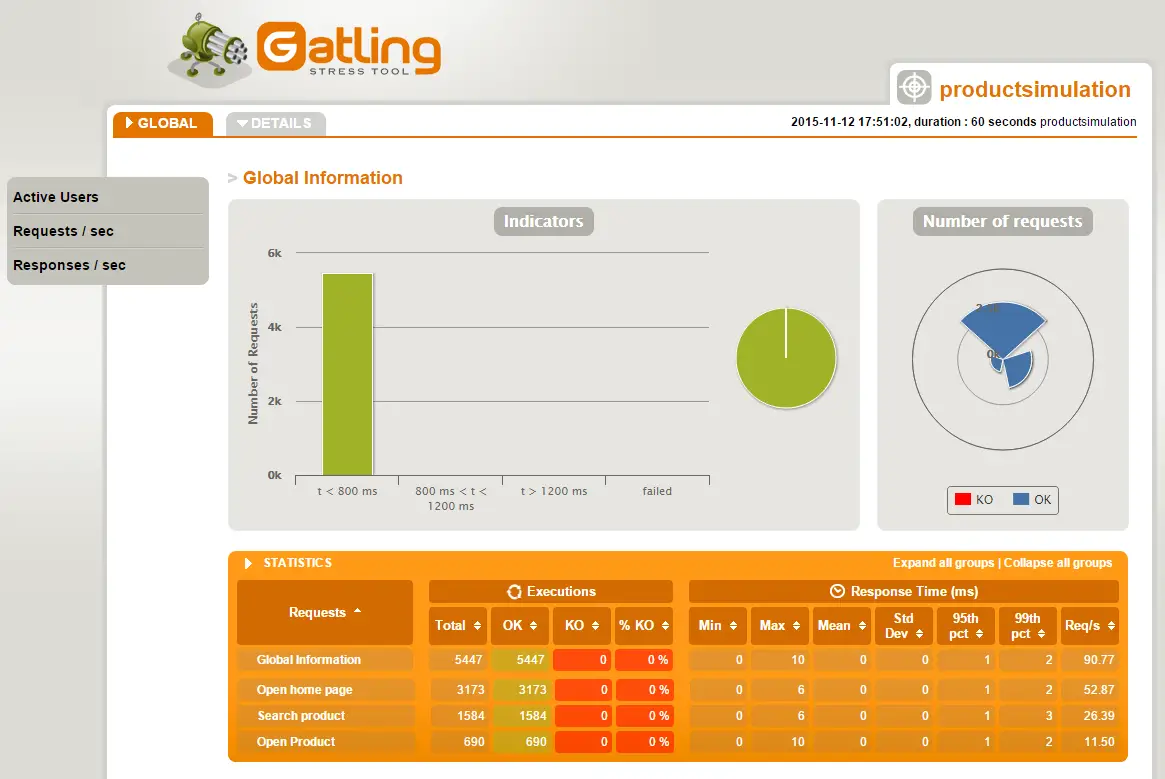
Shown above is just part of global information report page. There are following sections on it:
- Indicators – distribution in specified response time intervals: less than 800ms, 800ms – 1200ms, more 1200ms and failed. This can give you a general overview of the system performance. If the highest percentage of the responses are less than 800ms this is quite good performance indication.
- Number of requests – pie chart showing different request types. This gives visual information how many requests of different type are being sent. Type is actually the request name defined in http() method.
- STATISTICS – table with very detailed information what count of each request type has been sent, OK, KO count, KO percentage. There is information what is the best, worst and mean time for each request type. Since worst time could be for a single response this is not quite informative. This is why there is grouping what is the response time for 95% and 99% of the responses. Last information requests per second.
- Active Users along the Simulation – how many virtual users were sending requests at each moment during the simulation. There is also user count per scenario. The scenario is identified by its name defined in scenario() method.
- Response Time Distribution – detailed responses distribution in small time intervals. Pretty similar to Indicators one, but much more detailed, as time intervals are very small. This gives a much better perspective of performance as you can see what percentage of the requests are in given time bucket. This graphic also includes error requests as well.
- Response Time Percentiles over Time (OK) – minimum and maximum request time at each moment during simulation only for successful (OK) requests. There is also request grouping into percentage values showing what percent of the requests take given amount of time. Similar to STATISTICS table, but here there is much more detailed grouping and also you can see it distributed during simulation execution. Additionally, this graphic shows the number of user at each moment during simulation.
- Number of requests per second – how many requests are done to the server at each moment during simulation. There is separate graphics for all requests, OK and KO requests. Additionally, this graphic shows the number of user at each moment during simulation.
- Number of responses per second – how many responses are done to the server at each moment during simulation. There is separate graphics for all responses, OK and KO responses. Additionally, this graphic shows the number of user at each moment during simulation.
Gatling request details
Apart from the global information, there is a detailed report for each request type. Requests are sorted by name, used when defining the HTTP request in http() method. This is how request details look like:
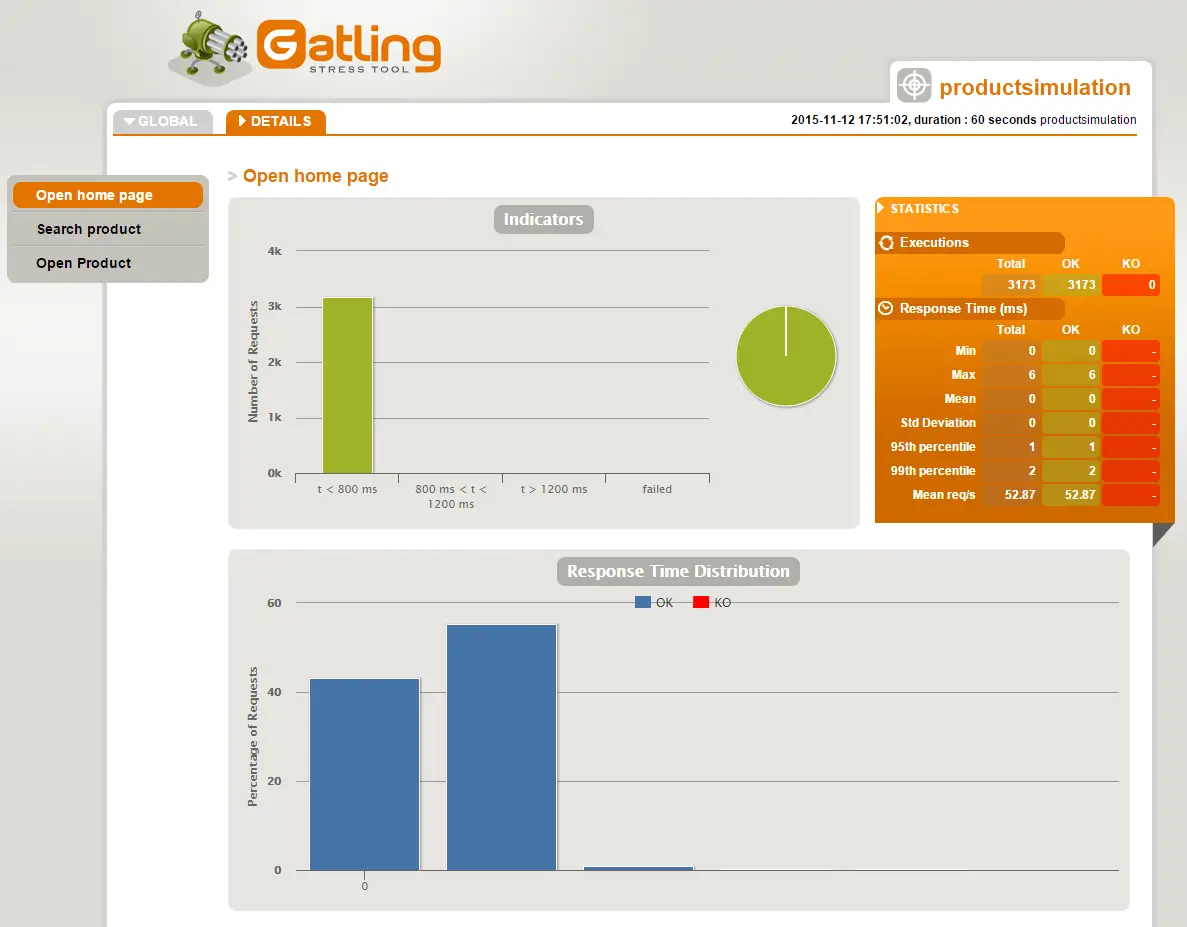
Shown above is just part of the request details report page. There are following sections on it:
- Indicators – same as in global information
- STATISTICS – same as in global information but just timing for this particular request are shown.
- Response Time Distribution – same as in global information
- Response Time Percentiles over Time (OK) – same as in global information
- Latency Percentiles over Time (OK) – same as Response Time Percentiles over Time (OK), but showing the time needed for the server to process the request, although it is incorrectly called latency. By definition Latency + Process Time = Response time. So this graphic is supposed to give the time needed for a request to reach the server. Checking real-life graphics I think this graphic shows not the Latency, but the real Process Time. You can get an idea of the real Latency by taking one and the same second from Response Time Percentiles over Time (OK) and subtract values from current graphs for the same second.
- Number of requests per second – same as in global information
- Number of responses per second – same as in global information
- Response Time against Global RPS – distribution of current request’s response time related to total request per second of the simulation.
- Latency against Global RPS – distribution of current request’s latency (process time) related to total request per second of the simulation.
Gatling data in simulation.log file
As you will see in the previous two sections Gatling gathers a limited amount of data, how many requests are made per any given time of the execution, are the responses OK or KO, what time each request and response take. All this information is stored into simulation.log file. Although the file is plain text data in it is understandable only by Gatling. In Performance testing with Gatling – advanced usage post, it is shown how you can extract more details from request and response. This gets recorded in simulation.log file, so be careful when doing this as this file might get enormous. View sample simulation.log file or sample Gatling report.
Conclusion
Gatling report is a valuable source of information to read the performance data by providing some details about requests and responses timing. The report should not be your main tool for finding issues when doing performance testing though. It is a good idea to have a server monitoring tool that gives more precise information about memory consumption and CPU. In case of bottlenecks identified by Gatling, it is mandatory to do some profiling of the application to understand what action on the server takes the longest time.