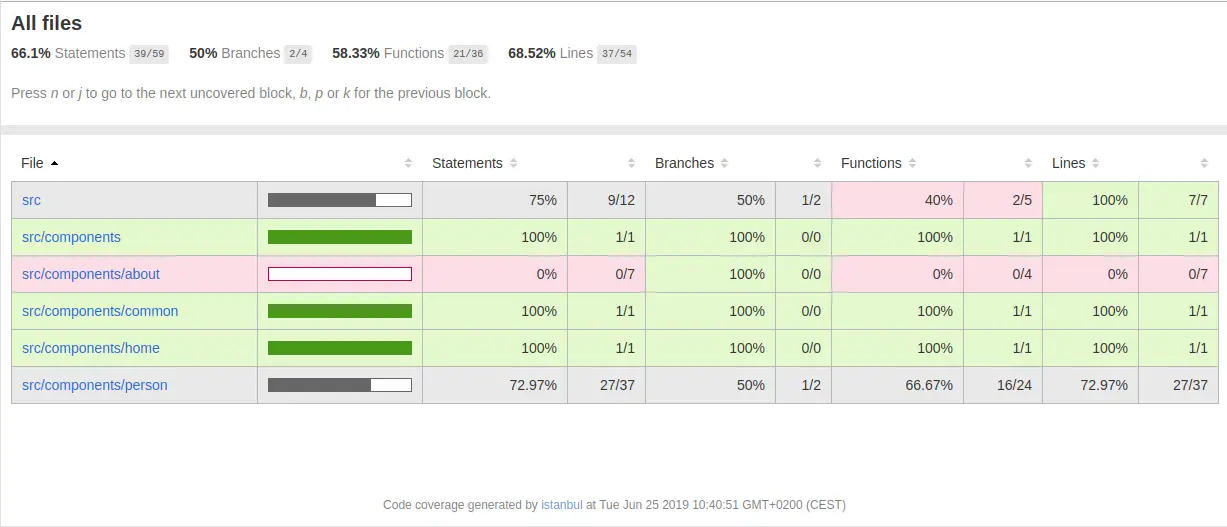
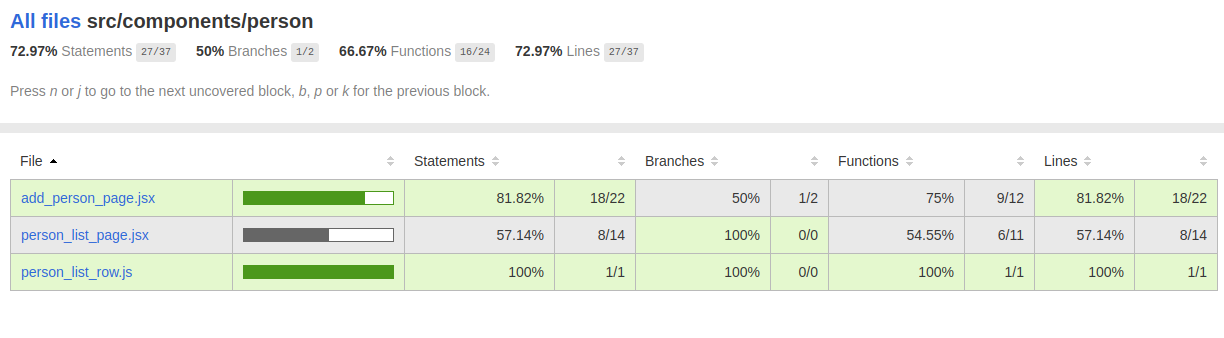
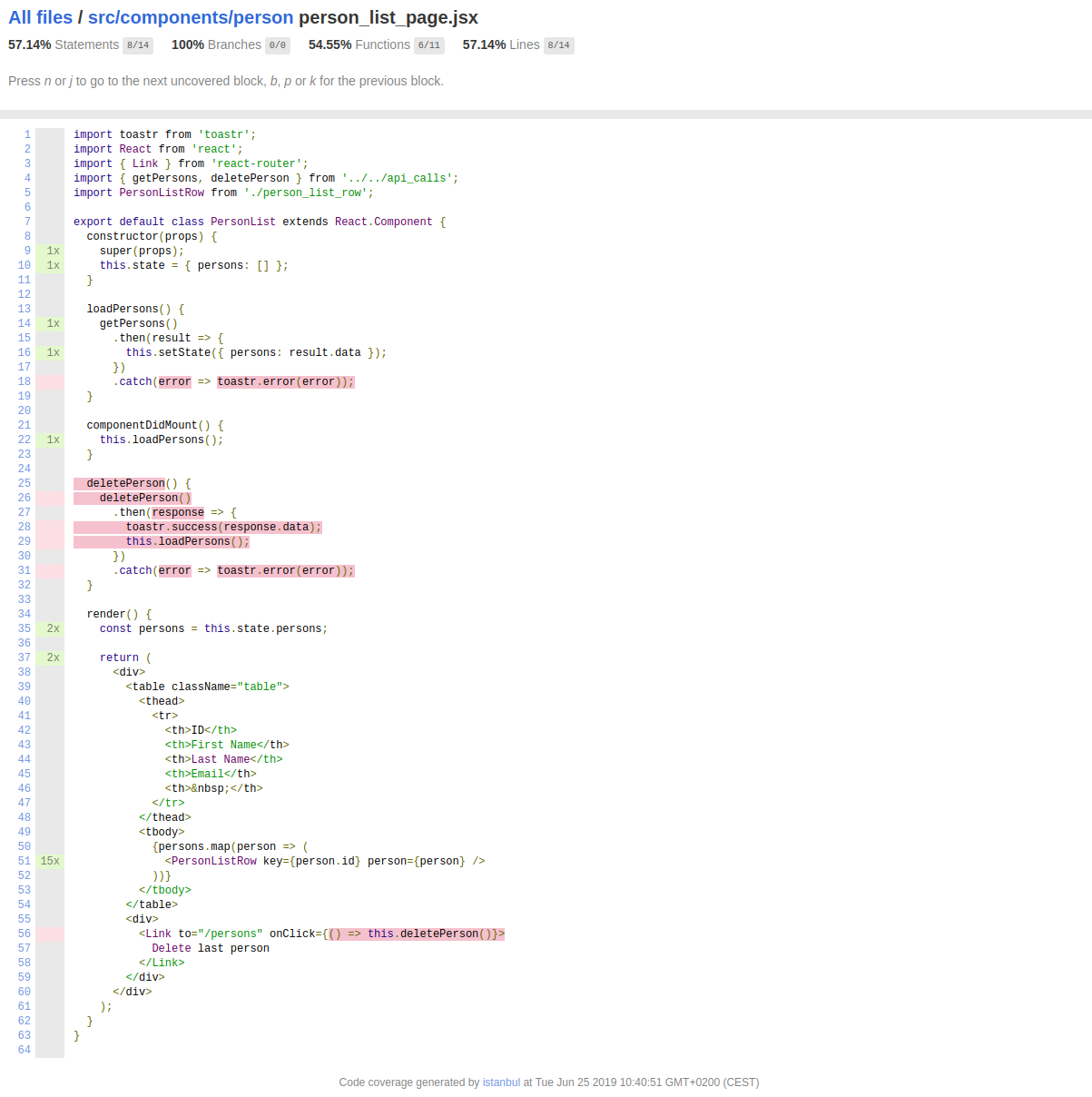
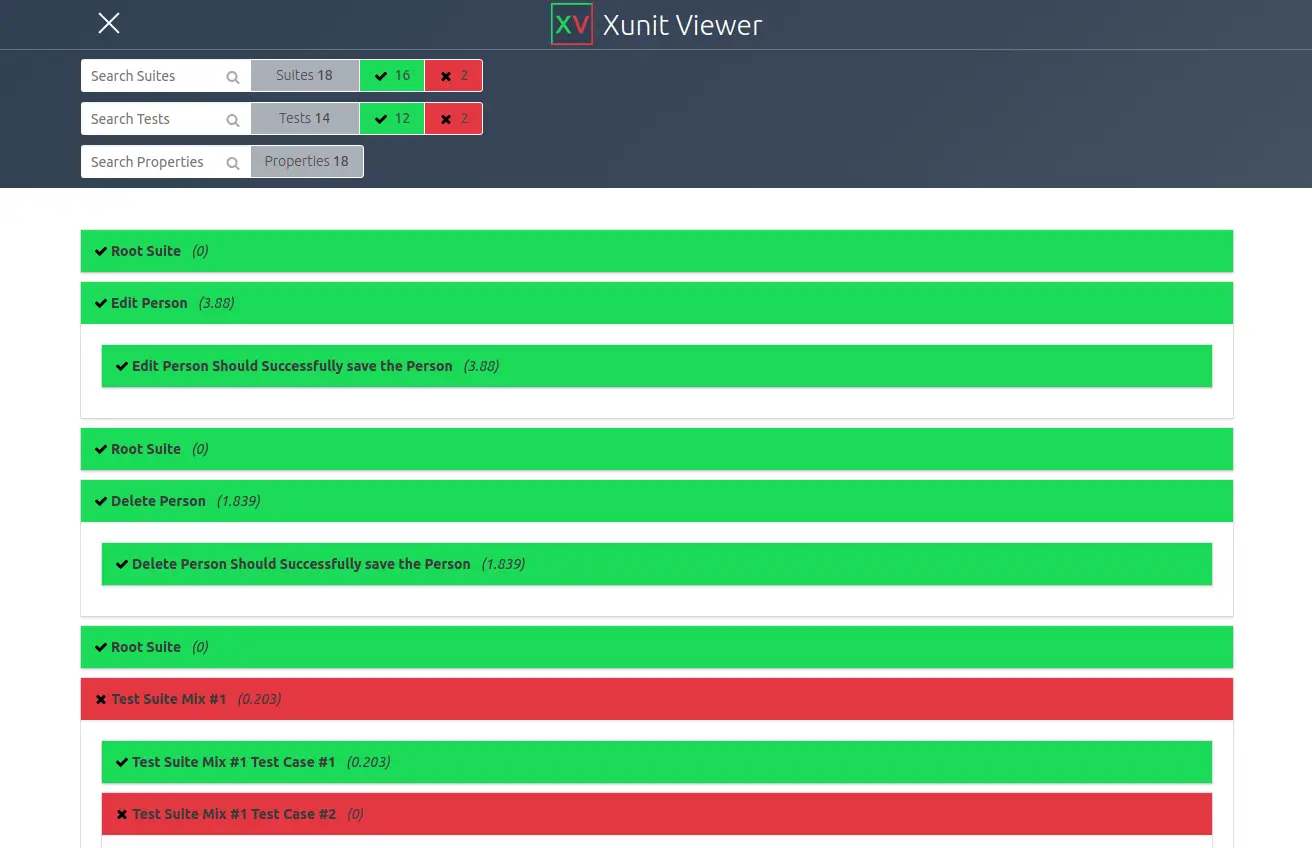
Post summary: Basic overview of the Cypress API with code samples for some of the interesting features.
This post is part of a Cypress series, you can see all post from the series in Testing with Cypress – lessons learned in a complete framework. Examples code is located in cypress-testing-framework GitHub repository.
Cypress API
Cypress is so much different than Selenium, so it takes some time to get used to the way elements are located and interacted with. I am not going into details about the API here but will mention some basic things. Methods in the API are kind of self-explanatory, mainly used ones are: get, find, click, type, first, last, prev, next, children, parent, etc.
Cypress uses jQuery selectors to locate elements, so you can have things like contains, nth-child, .class, #id, [name*=”value”] (and all variations). A very interesting and sometimes useful feature is that you can make Cypress click hidden elements with click({force: true}), Cypress gives you an error that element is not clickable from a user point of view, and you can choose to find another element or just force the click. Also, you can click multiple elements with click({multiple: true}).
Explore Cypress API
When every project is created for the first time, Cypress installs examples for all their APIs. Those are very good and extensive. I have preserved their examples in the current project and they are available in cypress/examples folder. You can run all the examples with yarn cypress:examples:run command. You can explore them one by one in the Test Runner, which can be opened with yarn cypress:examples:open command.
Page Object Model
As mentioned in the main topic, Cypress recommends using custom commands instead of Page Objects. I do not like this idea, so I use page objects, as I believe they make the code more focused. Here is an example of a page object I am conformable with:
export default class AboutPage {
constructor() {
this.elements = {
navigation: () => cy.getSilent('a[href$=about]'),
paragraph: index => cy.getSilent('section.m-3 div p').eq(index),
};
}
goTo() {
cy.visit('/');
this.elements.navigation().click();
}
/**
* @param {string} version
* @param {Date} datetime
*/
verifyPage(version, datetime) {
this.elements.paragraph(0)
.should('text', 'Welcome to the about page.');
this.elements.paragraph(1)
.should('text', `Current API version is: ${version}`);
this.elements.paragraph(2)
.should('text', `Current time is: ${datetime.toISOString()}`);
}
}
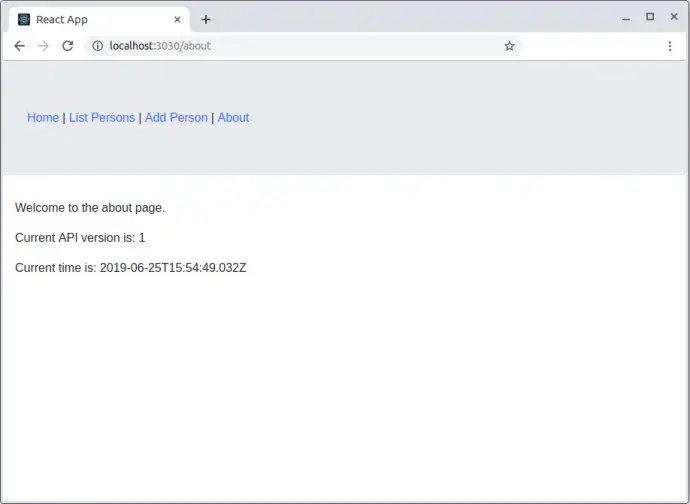
Clock
Cypress allows you to modify the clock in the browser. For e.g. About page of the application under test shows the current time. It makes much more easy to validate the visualization in case you control the current time. Otherwise, you have to parse the time and put some thresholds in the verifications.
Stub response
Another very handy feature is to be able to stub the response that API is supposed to return. In this way, you can very easily test for situations like timeout, incorrect response, error in response, etc.
Clock and Stub example
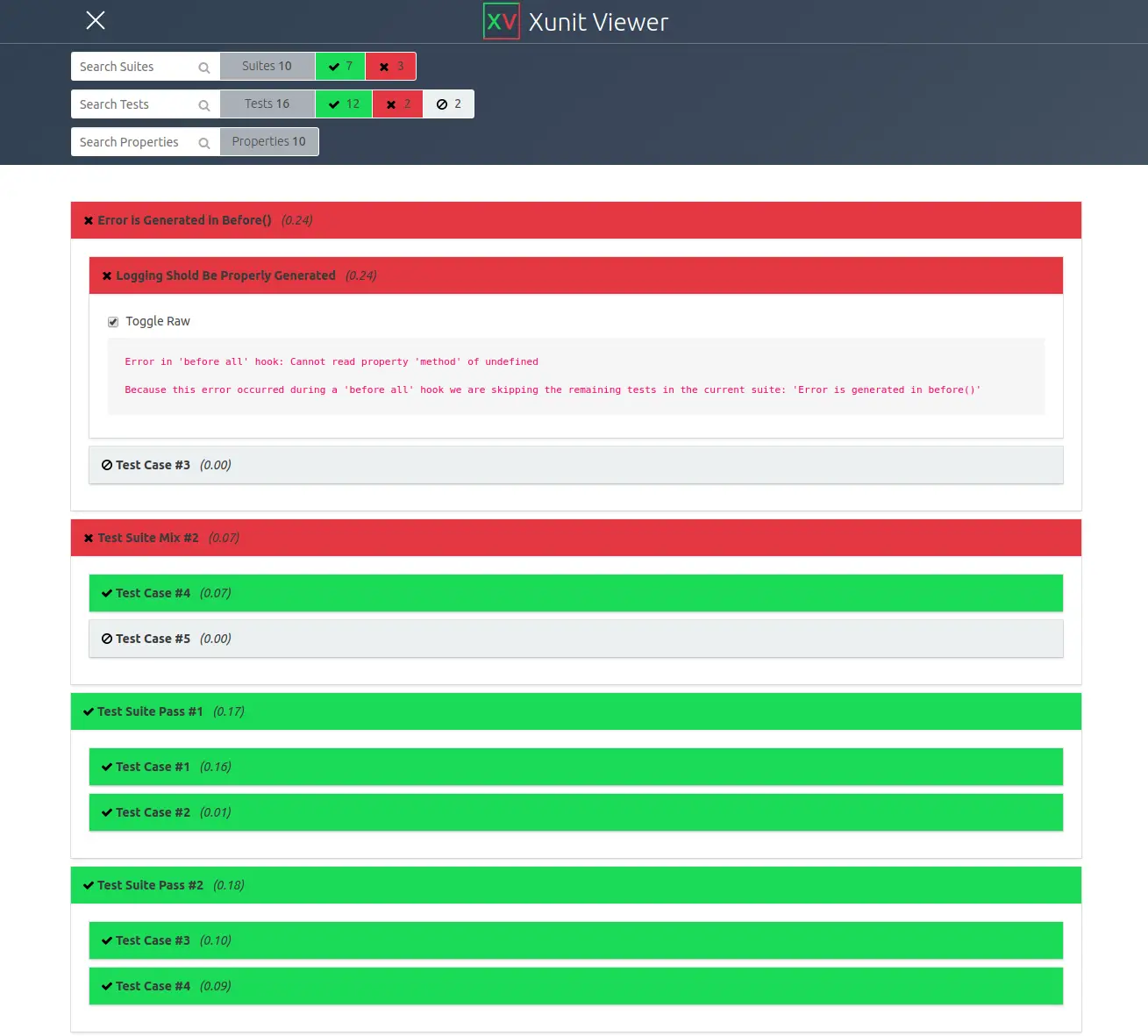
I have combined clock and stubbing into one example. The test suite file is cypress/tests/stub/response_and_clock_spec.js. The cy.clock(datetime.getTime()); sets the date to one you need. The cy.route(‘GET’, ‘/api/version’, version); simulates that API returns the version as a response. In the current case, it is a plain string, but in general case, this s JSON object.
response_and_clock_spec.js
import AboutPage from '../../pages/about_page';
describe('Check about page', () => {
it('should show correct stubbed data and clock', () => {
const aboutPage = new AboutPage();
const version = '2.33';
const datetime = new Date('2014-07-22T15:24:00');
cy.server();
cy.route('GET', '/api/version', version);
cy.clock(datetime.getTime());
aboutPage.goTo();
aboutPage.verifyPage(version, datetime);
});
});
about_page.js
verifyPage(version, datetime) {
this.elements.paragraph(0)
.should('text', 'Welcome to the about page.');
this.elements.paragraph(1)
.should('text', `Current API version is: ${version}`);
this.elements.paragraph(2)
.should('text', `Current time is: ${datetime.toISOString()}`);
}
Running custom Node.js code
Cypress runs into the browser, this is its biggest strength as you have direct access to your application and the browser. This is its weakness as well because the browser is much restrictive in terms of running code. In order to run custom Node.js code, you have to wrap it as a task. The Cypress task accepts only one argument, so if you need to pass more, you have to wrap them in a JSON object. The task should also return a promise. Tasks are registered into cypress/plugins/index.js file. See examples below. Task copyFile is used in cypress_loggin.js, a parameter that is passed to it is a JSON object with from and to keys. This task is registered with Cypress in index.js. Implementation is done in tasks.js where actual Node.js code is used to manipulate the file system and a Promise is returned.
cypress_logging.js
cy.task('copyFile', {
from: `cypress/screenshots/${screenshotFilename}`,
to: getFilePath(screenshotFilename),
});
index.js
const tasks = require('./tasks');
module.exports = (on, config) => {
// `on` is used to hook into various events Cypress emits
on('task', {
copyFile: tasks.copyFile,
});
// `config` is the resolved Cypress config
const newConfig = config;
newConfig.watchForFileChanges = false;
return newConfig;
};
tasks.js
const fs = require('fs');
const copyFile = args =>
new Promise(resolve => {
if (fs.existsSync(args.from)) {
fs.writeFileSync(args.to, fs.readFileSync(args.from));
resolve(`File ${args.from} copied to ${args.to}`);
}
resolve(`File ${args.from} does not exist`);
});
module.exports = { copyFile };
Working with promises
Cypress is based on promises. Each Cypress command returns a command which is similar to a promise, but actually is different, read mode in Commands Are Not Promises. If you want to access the value from the previous operation you have to unwrap it with a then() method. If you have several dependencies then this nesting becomes bigger and bigger. This is why I have adopted some code from Nicholas Boll to avoid nesting. The article above is about using async/await but actually, it is not going to work with my custom logging, I will write in the next section. Initially, I started using directly the plugin from Nicholas, but I have observed strange bugs where a test fails but is not reported as such, so I modified it and it is proved stable now.
See examples below. The standard way of doing it is by unwrapping the command with the then() method. This is working but can get really ugly if you have too many nested unwrappings. The option is to use promisify() which wraps the Cypress command into a promise. The promise is then resolved only inside some other Cypress command, such as cy.log() or custom command cy.apiGetPerson(). If you print it directly the result in the console is a Promise.
with unwrap
it('should work with regular unwrap', () => {
const person = new Person();
// This is a command
cy.apiSavePerson(person).then(personId => {
// Value is unwrapped and printed properly
cy.log(personId);
console.log(personId);
// Value is passed unwrapped
cy.apiGetPerson(personId).then(res => cy.log(res));
});
});
with promisify()
it('should work with promisify', () => {
const person = new Person();
// This is a promise
const personId = cy.apiSavePerson(person).promisify();
// Cypress internally resolves the promise
cy.log(personId);
// Prints a Promise
console.log(personId);
// Value is accessible after unwrap
personId.then(pid => console.log(pid));
// Cypress internally unwraps the value
cy.apiGetPerson(personId).then(res => cy.log(res));
});
cypress_promisify.js
function promisify(chain) {
return new Cypress.Promise((resolve, reject) => {
chain.then(resolve);
});
}
before(function() {
cy.wrap('').__proto__.promisify = function() {
return promisify(this);
};
});
Working with async/await
The code above should work with async/await, which is an amazing JavaScript feature. It does work but it messes up with the custom logging I have described into Testing with Cypress – Custom logging of errors and JUnit results post. The code below works, but the custom logging is not triggered. So I would say, do not use async/await if you need those customizations. The bigger issue is that async/await does not seem to work in Electron, cy.apiGetPerson() is actually not invoked if you run the code in Electron browser.
it('should work with async/await', async () => {
const person = new Person();
// This is a resolved promise
const personId = await cy.apiSavePerson(person).promisify();
// Value is wrapped and printed properly
cy.log(personId);
console.log(personId);
// Value is passed unwrapped
cy.apiGetPerson(personId).then(res => cy.log(res));
});
Full API documentation
Cypress has very good and extensive documentation, you can read more at Cypress API article.
Conclusion
Cypress has a rich API which requires some time investments to get used to. You have good things like controlling the clock of the browser, controlling the API response from the backend. Good thing is that you have a way to run whatever code you want in your tests, but it has to wrapped as a task, otherwise you cannot just run any code in the browser.
Related Posts