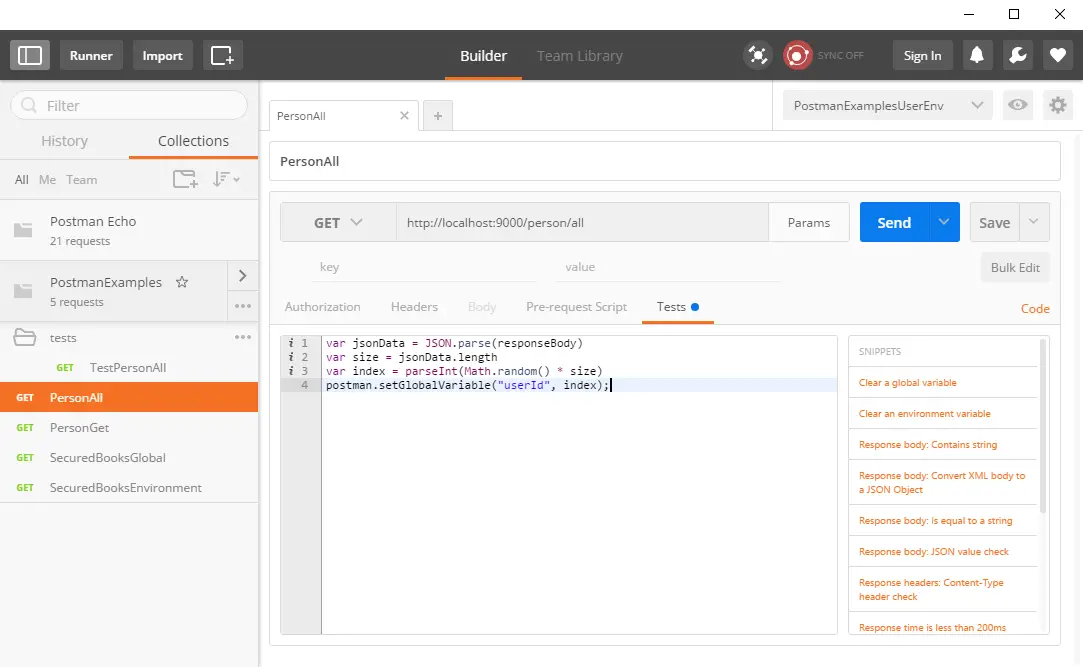
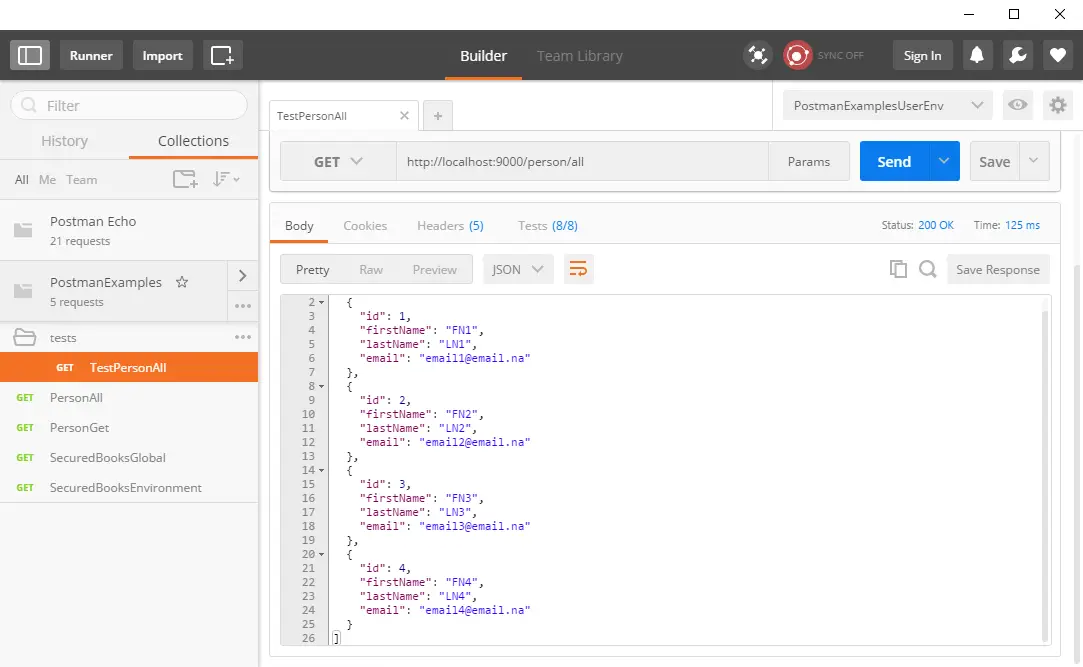
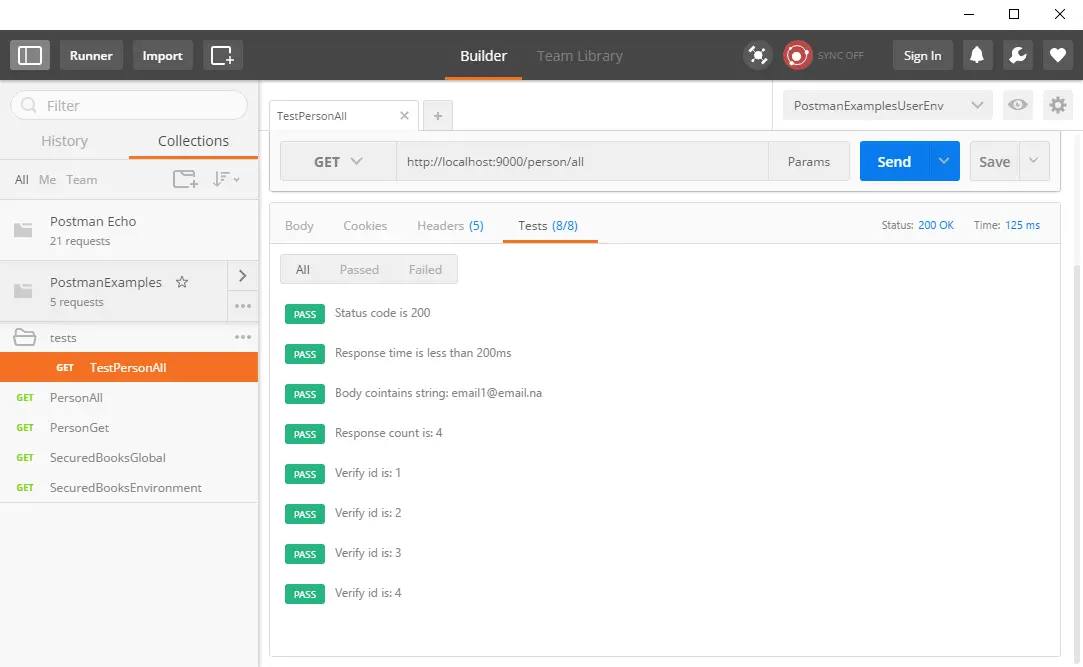
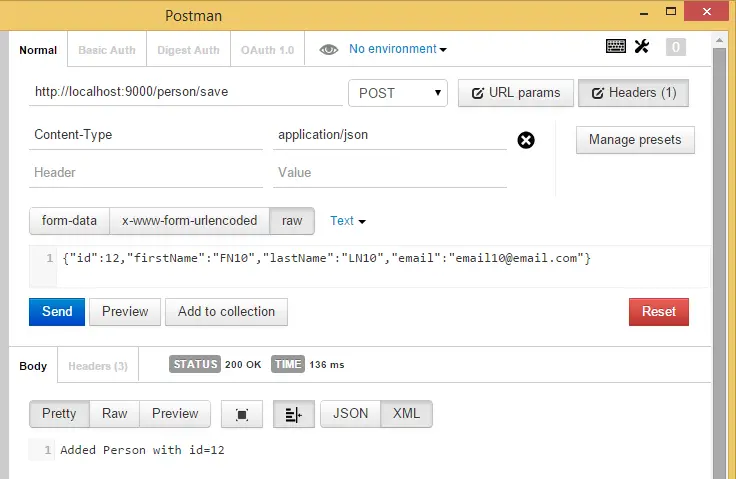
Post summary: How to do integration testing on .NET Core application and stub or mock some inconvenient dependencies.
Code below can be found in GitHub SampleDotNetCore2RestStub repository. In Build a REST API with .NET Core 2 and run it on Docker Linux container post I have shown how to create .NET Core application. In the current post, I will show how to do integration testing on the same application. The post is for REST API, but principles here apply for web UI as well, the difference is that the response will be HTML, which is slightly harder to process compared to JSON.
Refactor project structure
Currently, there is only one project created which contains .NET Core application. Since this is going to grow it has to be refactored and structured properly.
- SampleDotNetCore2RestStub folder which contains the API is moved to src folder.
- Solution file is created with dotnet new sln –name SampleDotNetCore2RestStub. Note that .sln extension is omitted as it is added automatically. Although everything in the example is done with open source tools, it is good to have solution file to keep compatibility with Visual Studio 2017.
- API project file is added to solution file with:
dotnet sln SampleDotNetCore2RestStub.sln add src/SampleDotNetCore2RestStub/SampleDotNetCore2RestStub.csproj. - In order to test that moving of files did not affected the functionality, API can be run with: dotnet run –project src/SampleDotNetCore2RestStub/SampleDotNetCore2RestStub.csproj.
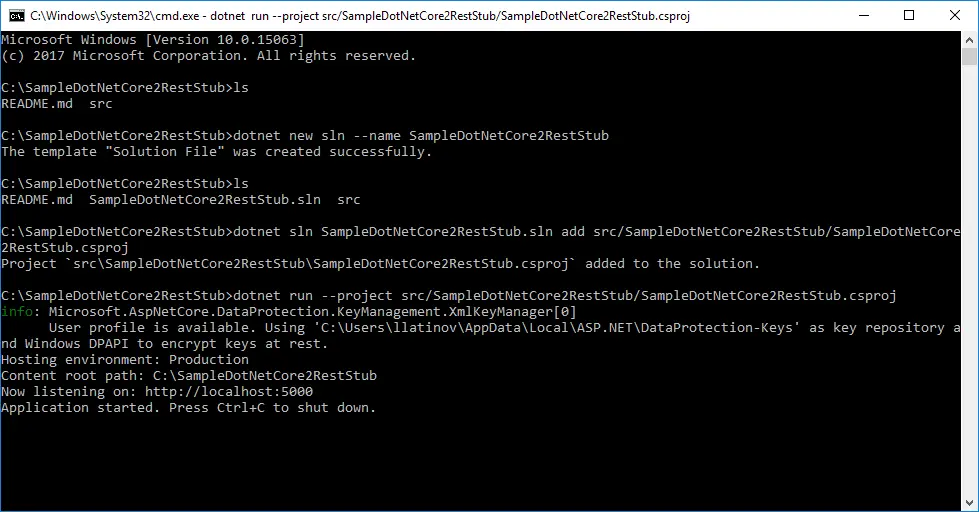
Add test project
It is time to create integration tests project. We speak for integration tests, but they will be run with unit testing framework MSTest. I do not have some particular favor of it, it comes by default with .NET Core, along with xUnit, and I do not want to change it.
- Create test folder: mkdir test.
- Navigate to it: cd test.
- MSTest project is created with: dotnet new mstest -o SampleDotNetCore2RestStub.Integration.Test.
- Navigate to test project: cd SampleDotNetCore2RestStub.Integration.Test.
- Run the unit tests: dotnet test. By default, there is one dummy test that passes.
- Go to root folder: cd .. and cd ..
- Add test project to solution file: dotnet sln SampleDotNetCore2RestStub.sln add test/SampleDotNetCore2RestStub.Integration.Test/SampleDotNetCore2RestStub.Integration.Test.csproj.
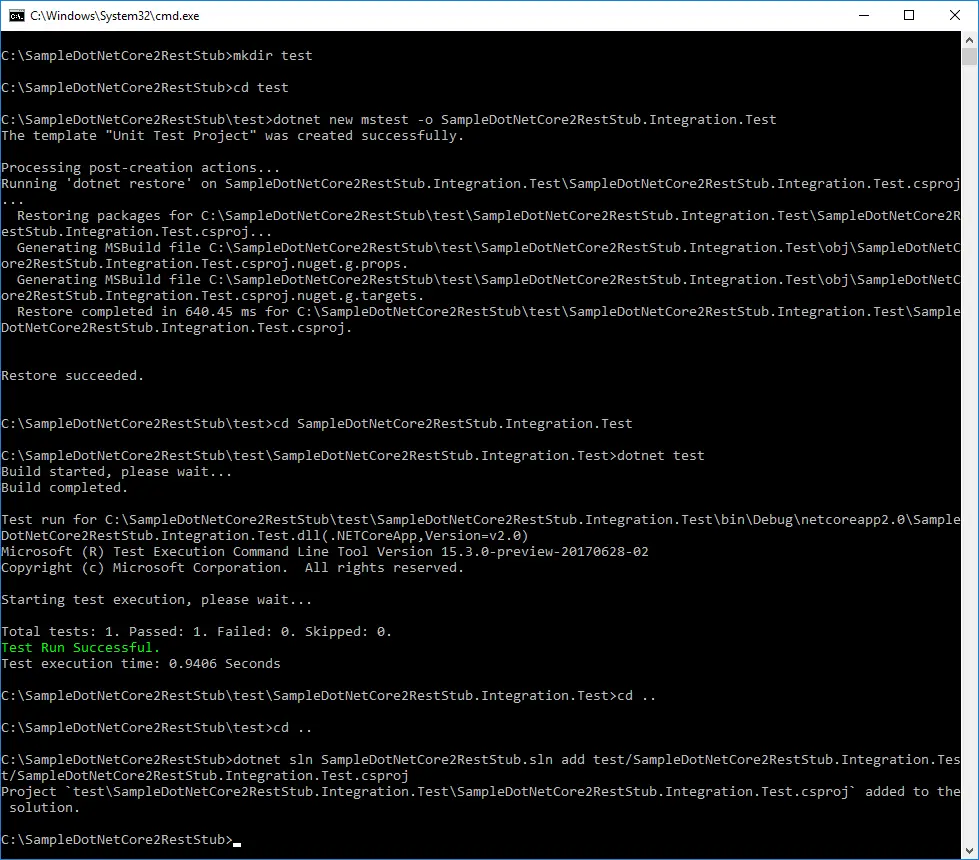
Open with Visual Studio Code
Once refactored and opened in Visual Studio Code project has following structure:
Unit vs Integration testing
I would not like to focus on theory and terminology as this post is not intended to, but I have to do some theoretical setup before proceeding with the code. Generally speaking, term integration testing is used in two cases. One is when different systems are interconnected together and tested, other is when different components of one system are grouped together and tested. In the current post with term integration testing, I will refer the latter. In unit testing, each separate class is tested in isolation. In order to do so all external dependencies, like a database, file system, web requests, and response, etc., are mocked. This makes tests run very fast but has a very high risk of false positives because of mocking. When mocking a dependency there is always an assumption how it works and is being used. The mocked behavior might be significantly different than actual one, then the unit test is compromised. On the other hand, integration testing verifies that different parts of the application work correctly when grouped together. It is much slower than unit testing because more and real resources are being used. Some parts of the application still can be mocked which can increase execution time. In the current post, I will show how to run a full application with only the database being mocked.
The Test Host
One way to run the fully assembled application is by building and deploying it. Then, the application will use real resources to work. Functional testing should also be done during testing but is not part of the current post. A more interesting scenario is to run fully assembled or partially mocked application in memory, without deployment and run tests against it. This approach has benefits, e.g. since the application is run locally its response time is very low, which speeds up tests; some parts, like database connection, can be mocked and thus speed up tests. .NET Core Test Host is a tool that can host web or API .NET Core applications serving requests and responses. It eliminates the need for having a testing environment.
Add dependencies
In order to use test host dependency to its NuGet package should be added. Navigate to test/SampleDotNetCore2RestStub.Integration.Test and add a dependency:
dotnet add package Microsoft.AspNetCore.TestHost
SampleDotNetCore2RestStub.Integration.Test project should depend on SampleDotNetCore2RestStub in order to use its code. This is done with:
dotnet add reference ../../src/SampleDotNetCore2RestStub/SampleDotNetCore2RestStub.csproj
Create the first test
Existing UnitTest1 class will be changed to start application inside test host and make a request.
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Newtonsoft.Json;
using SampleDotNetCore2RestStub.Models;
namespace SampleDotNetCore2RestStub.Integration.Test
{
[TestClass]
public class PersonsTest
{
private TestServer _server;
private HttpClient _client;
[TestInitialize]
public void TestInitialize()
{
_server = new TestServer(new WebHostBuilder()
.UseStartup<Startup>());
_client = _server.CreateClient();
}
[TestMethod]
public async Task GetPerson()
{
var response = await _client.GetAsync("/person/get/1");
response.EnsureSuccessStatusCode();
var result = await response.Content.ReadAsStringAsync();
var person = JsonConvert.DeserializeObject<Person>(result);
Assert.AreEqual("LN1", person.LastName);
}
}
}
TestServer uses an instance of IWebHostBuilder. Startup from UseStartup<Startup> is same class that is used to run the application, but here it is run inside TestServer instance. CreateClient() method returns instance of standard HttpClient, with which request to /person/get/1 endpoint is made. EnsureSuccessStatusCode() throws exception if response code is not inside 200-299 range. The response is then taken as a string and deserialized to Person object with Newtonsoft.Json, which is now part of .NET Core.
Test can be run from test\SampleDotNetCore2RestStub.Integration.Test folder with the command: dotnet test. If you type dotnet test from root folder it will search for tests inside all projects.
Debug tests in Visual Studio Code
Before proceeding any further with the code it should be possible to debug unit tests inside VS Code. It is not as easy as with VS 2017, but still manageable. First, you need to run your test from the command prompt in debug mode:
set VSTEST_HOST_DEBUG=1
dotnet test
Once this is done there is a message with specific process ID:
Starting test execution, please wait...
Host debugging is enabled. Please attach debugger to testhost process to continue.
Process Id: 16032, Name: dotnet
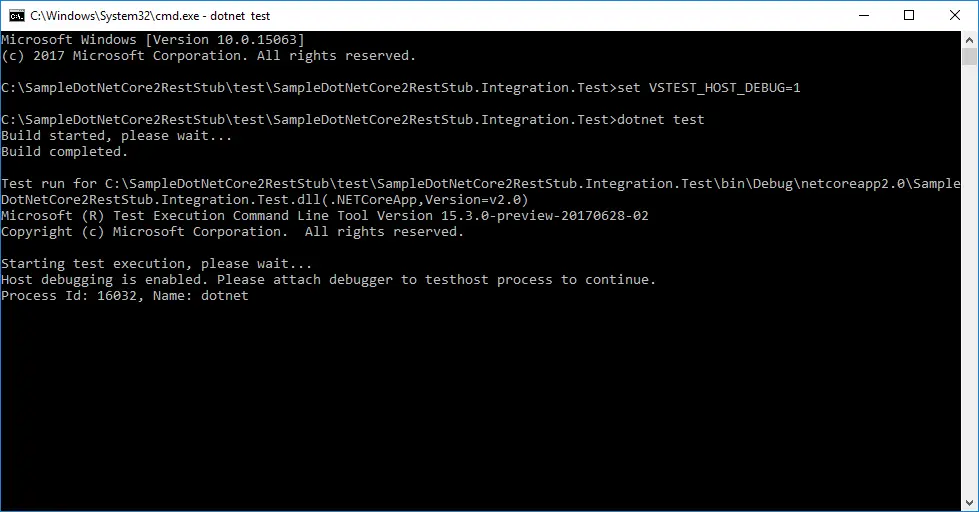
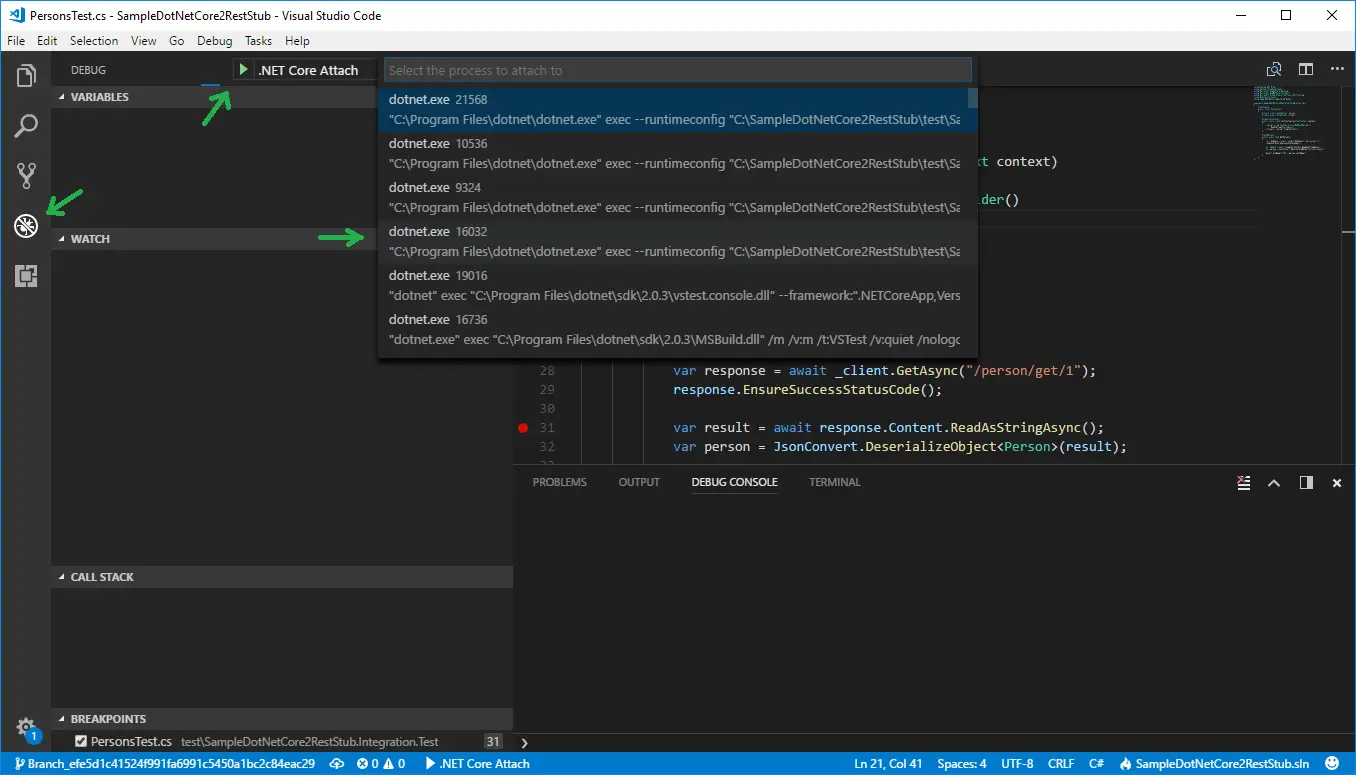
Now from Visual Studio Code, you have to attach to given process, 16032 in the current example. This is done from Debug View, then select .Net Core Attach launch configuration. If such is not existing, add it. Running this configuration shows a list of all processes with name dotnet. Select the proper one, 16032 in the current example.
Create PersonServiceClient and BaseTest
Tests should be easy to write, read and maintain, thus PersonServiceClient class is created. It exposes methods that hit the endpoints and return the result. Since testing is not only happy path, it should be possible to have some negative scenarios. You may want to hit the API with invalid data and verify it returns BadRequest (400) HTTP response code, or Unauthorized (401) HTTP response code, etc. In order to fulfill this test requirement, a separate class ApiResponse<T> is created. It stores response code along with response content as a string. In case that response string can be deserialized to an object of given generic type T it is also stored in ApiResponse object.
Client is instantiated as a protected variable in BaseTest constructor. PersonsTest extends BaseTest and has access to PersonServiceClient.
ApiResponse
using System.Net;
namespace SampleDotNetCore2RestStub.Integration.Test.Client
{
public class ApiResponse<T>
{
public HttpStatusCode StatusCode { get; set; }
public T Result { get; set; }
public string ResultAsString { get; set; }
}
}
PersonServiceClient
using System;
using System.Collections.Generic;
using System.Net.Http;
using System.Threading.Tasks;
using Newtonsoft.Json;
using SampleDotNetCore2RestStub.Models;
namespace SampleDotNetCore2RestStub.Integration.Test.Client
{
public class PersonServiceClient
{
private readonly HttpClient _httpClient;
public PersonServiceClient(HttpClient httpClient)
{
_httpClient = httpClient;
}
public async Task<ApiResponse<Person>> GetPerson(string id)
{
var person = await GetAsync<Person>($"/person/get/{id}");
return person;
}
public async Task<ApiResponse<List<Person>>> GetPersons()
{
var persons = await GetAsync<List<Person>>("/person/all");
return persons;
}
public async Task<ApiResponse<string>> Version()
{
var version = await GetAsync<string>("api/version");
return version;
}
private async Task<ApiResponse<T>> GetAsync<T>(string path)
{
var response = await _httpClient.GetAsync(path);
var value = await response.Content.ReadAsStringAsync();
var result = new ApiResponse<T>
{
StatusCode = response.StatusCode,
ResultAsString = value
};
try
{
result.Result = JsonConvert.DeserializeObject<T>(value);
}
catch (Exception)
{
// Nothing to do
}
return result;
}
}
}
BaseTest
using System.Net.Http;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using SampleDotNetCore2RestStub.Integration.Test.Client;
namespace SampleDotNetCore2RestStub.Integration.Test
{
public abstract class BaseTest
{
protected PersonServiceClient PersonServiceClient;
public BaseTest()
{
var server = new TestServer(new WebHostBuilder()
.UseStartup<Startup>());
var httpClient = server.CreateClient();
PersonServiceClient = new PersonServiceClient(httpClient);
}
}
}
PersonsTest
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Newtonsoft.Json;
using SampleDotNetCore2RestStub.Models;
namespace SampleDotNetCore2RestStub.Integration.Test
{
[TestClass]
public class PersonsTest : BaseTest
{
[TestMethod]
public async Task GetPerson()
{
var response = await PersonServiceClient.GetPerson("1");
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual("LN1", response.Result.LastName);
}
[TestMethod]
public async Task GetPersons()
{
var response = await PersonServiceClient.GetPersons();
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual(4, response.Result.Count);
Assert.AreEqual("LN1", response.Result[0].LastName);
}
}
}
Stub the database
So far there is integration test that starts the application with its actual external dependencies and makes requests against it. Current API service does not connect to a real database, because this will make running the API harder. Instead, there is a fake PersonRepository which stores data in memory. In reality, the repository will connect to a database with a given connection string in appsettings.json, and will perform CRUD operations on it. Database operations might slow down the application response time, or test might not have full control over data in the database, which makes testing harder. In order to solve those two issues database can be stubbed to serve test data. Actually, anything that is not convenient can be stubbed with the examples given below.
In order to make stubbing possible and to keep application structure intact Startup has to be changed. Registering PersonRepository to .NET Core IoC container is extracted to separate virtual method that can be overridden later. All dependencies that are to be stubbed or mocked can be extracted to such methods. Then StartupStub overrides this method and registers stubbed repository PersonRepositoryStub. In it all database operations are substituted with an in-memory equivalence, hence skipping database calls. It might not be a full and accurate substitution, as long as it serves your testing purpose. After all this PersonRepositoryStub will be used only for testing. BaseTest should be changed to start the application with StartupStub instead of Statup. Finally, PersonsTest should be changed to assert on new data that is configured in PersonRepositoryStub.
Startup
public void ConfigureServices(IServiceCollection services)
{
services.AddMvc();
services.Configure<AppConfig>(Configuration);
services.AddScoped<AuthenticationFilterAttribute>();
ConfigureRepositories(services);
}
public virtual void ConfigureRepositories(IServiceCollection services)
{
services.AddSingleton<IPersonRepository, PersonRepository>();
}
StartupStub
using Microsoft.Extensions.DependencyInjection;
using SampleDotNetCore2RestStub.Repositories;
namespace SampleDotNetCore2RestStub.Integration.Test.Mocks
{
public class StartupStub : Startup
{
public override void ConfigureRepositories(IServiceCollection services)
{
services.AddSingleton<IPersonRepository, PersonRepositoryStub>();
}
}
}
PersonRepositoryStub
using System.Collections.Generic;
using System.Linq;
using SampleDotNetCore2RestStub.Models;
using SampleDotNetCore2RestStub.Repositories;
namespace SampleDotNetCore2RestStub.Integration.Test.Mocks
{
public class PersonRepositoryStub : IPersonRepository
{
private Dictionary<int, Person> _persons
= new Dictionary<int, Person>();
public PersonRepositoryStub()
{
_persons.Add(1, new Person
{
Id = 1,
FirstName = "Stubed FN1",
LastName = "Stubed LN1",
Email = "stubed.email1@email.na"
});
}
public Person GetById(int id)
{
return _persons[id];
}
public List<Person> GetAll()
{
return _persons.Values.ToList();
}
public int GetCount()
{
return _persons.Count();
}
public void Remove()
{
if (_persons.Keys.Any())
{
_persons.Remove(_persons.Keys.Last());
}
}
public string Save(Person person)
{
if (_persons.ContainsKey(person.Id))
{
_persons[person.Id] = person;
return "Updated Person with id=" + person.Id;
}
else
{
_persons.Add(person.Id, person);
return "Added Person with id=" + person.Id;
}
}
}
}
BaseTest
using System.Net.Http;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using SampleDotNetCore2RestStub.Integration.Test.Client;
using SampleDotNetCore2RestStub.Integration.Test.Mocks;
namespace SampleDotNetCore2RestStub.Integration.Test
{
public abstract class BaseTest
{
protected PersonServiceClient PersonServiceClient;
public BaseTest()
{
var server = new TestServer(new WebHostBuilder()
.UseStartup<StartupStub>());
var httpClient = server.CreateClient();
PersonServiceClient = new PersonServiceClient(httpClient);
}
}
}
PersonsTest
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Newtonsoft.Json;
using SampleDotNetCore2RestStub.Models;
namespace SampleDotNetCore2RestStub.Integration.Test
{
[TestClass]
public class PersonsTest : BaseTest
{
[TestMethod]
public async Task GetPerson()
{
var response = await PersonServiceClient.GetPerson("1");
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual("Stubed LN1", response.Result.LastName);
}
[TestMethod]
public async Task GetPersons()
{
var response = await PersonServiceClient.GetPersons();
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual(1, response.Result.Count);
Assert.AreEqual("Stubed LN1", response.Result[0].LastName);
}
}
}
Mock the database
Stubbing is an option, but mocking is much better as you have direct control over the mock itself. The most famous .NET mocking framework is Moq. It is added to the project with the command:
dotnet add package Moq
StartupMock extends Starup and overrides its ConfigureRepositories. It registers an instance of IPersonRepository which is injected by its constructor. BaseTest is changed to use StartupMock in UseStartup method. Repository mock is instantiated with PersonRepositoryMock = new Mock<IPersonRepository>(). It is injected into StartupMock constructor with ConfigureServices(services => services.AddSingleton(PersonRepositoryMock.Object)). This is how mock instance is registered into IoC container of .NET Core application that is being tested. Once the mock instance is registered it can be controlled. In BaseTest it is reset to defaults after each test with BaseTearDown method. It is run after each test because of [TestCleanup] MSTest attribute. Inside, the PersonRepositoryMock.Reset() resets mock state.
Test specific setup can be done for each test. For e.g. GetPerson_ReturnsCorrectResult has following setup: PersonRepositoryMock.Setup(x => x.GetById(It.IsAny<int>())).Returns(_person); That means when mock’s GetById method is called with whatever int value the _person object is returned. Another example is GetPerson_ThrowsException test. When mock’s GetById is called then InvalidOperationException is thrown. In this way, you can test exception handling, which in current demo application is missing. The exception is not that easy to reproduce if you are using repository stubbing.
StartupMock
using Microsoft.Extensions.DependencyInjection;
using SampleDotNetCore2RestStub.Repositories;
namespace SampleDotNetCore2RestStub.Integration.Test.Mocks
{
public class StartupMock : Startup
{
private IPersonRepository _personRepository;
public StartupMock(IPersonRepository personRepository)
{
_personRepository = personRepository;
}
public override void ConfigureRepositories(IServiceCollection services)
{
services.AddSingleton(_personRepository);
}
}
}
BaseTest
using System.Net.Http;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Microsoft.Extensions.DependencyInjection;
using Moq;
using SampleDotNetCore2RestStub.Integration.Test.Client;
using SampleDotNetCore2RestStub.Integration.Test.Mocks;
using SampleDotNetCore2RestStub.Repositories;
namespace SampleDotNetCore2RestStub.Integration.Test
{
public abstract class BaseTest
{
protected PersonServiceClient PersonServiceClient;
protected Mock<IPersonRepository> PersonRepositoryMock;
public BaseTest()
{
PersonRepositoryMock = new Mock<IPersonRepository>();
var server = new TestServer(new WebHostBuilder()
.UseStartup<StartupMock>()
.ConfigureServices(services =>
{
services.AddSingleton(PersonRepositoryMock.Object);
}));
var httpClient = server.CreateClient();
PersonServiceClient = new PersonServiceClient(httpClient);
}
[TestCleanup]
public void BaseTearDown()
{
PersonRepositoryMock.Reset();
}
}
}
PersonsTest
using System;
using System.Collections.Generic;
using System.Net;
using System.Net.Http;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.TestHost;
using Microsoft.VisualStudio.TestTools.UnitTesting;
using Moq;
using Newtonsoft.Json;
using SampleDotNetCore2RestStub.Models;
namespace SampleDotNetCore2RestStub.Integration.Test
{
[TestClass]
public class PersonsTest : BaseTest
{
private readonly Person _person = new Person
{
Id = 1,
FirstName = "Mocked FN1",
LastName = "Mocked LN1",
Email = "mocked.email1@email.na"
};
[TestMethod]
public async Task GetPerson_ReturnsCorrectResult()
{
PersonRepositoryMock.Setup(x => x.GetById(It.IsAny<int>()))
.Returns(_person);
var response = await PersonServiceClient.GetPerson("1");
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual("Mocked LN1", response.Result.LastName);
}
[TestMethod]
[ExpectedException(typeof(InvalidOperationException))]
public async Task GetPerson_ThrowsException()
{
PersonRepositoryMock.Setup(x => x.GetById(It.IsAny<int>()))
.Throws(new InvalidOperationException());
var result = await PersonServiceClient.GetPerson("1");
}
[TestMethod]
public async Task GetPersons()
{
PersonRepositoryMock.Setup(x => x.GetAll())
.Returns(new List<Person> { _person });
var response = await PersonServiceClient.GetPersons();
Assert.AreEqual(HttpStatusCode.OK, response.StatusCode);
Assert.AreEqual(1, response.Result.Count);
Assert.AreEqual("Mocked LN1", response.Result[0].LastName);
}
}
}
Nicer database mock
As of version 2.1.0 of Microsoft.AspNetCore.TestHost, which is currently in pre-release, there is a method called ConfigureTestServices, which saves us from having separate StartupMock class. You can directly inject your mocks with following code:
var server = new TestServer(new WebHostBuilder()
.UseStartup<Startup>()
.ConfigureTestServices(services =>
{
services.AddSingleton(PersonRepositoryMock.Object);
}));
Conclusion
In the current post, I have shown how to do integration testing on .NET Core applications. This is a very convenient approach which eliminates some of the disadvantages of stubbing or mocking all dependencies in unit testing. Because of using all dependencies, integration testing can be much slower. This can be improved by mocking some of them. Integration testing is not a substitute for unit testing, nor for functional testing, but it is a good approach in you testing portfolio that should be considered.