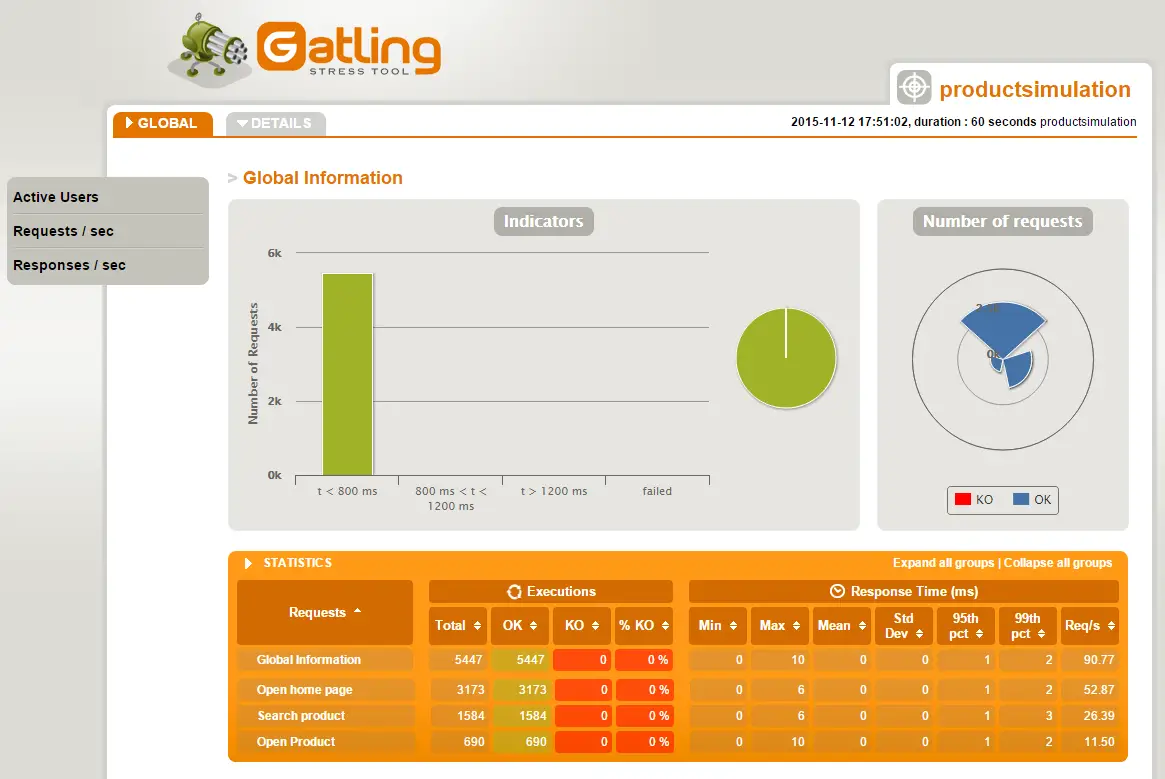
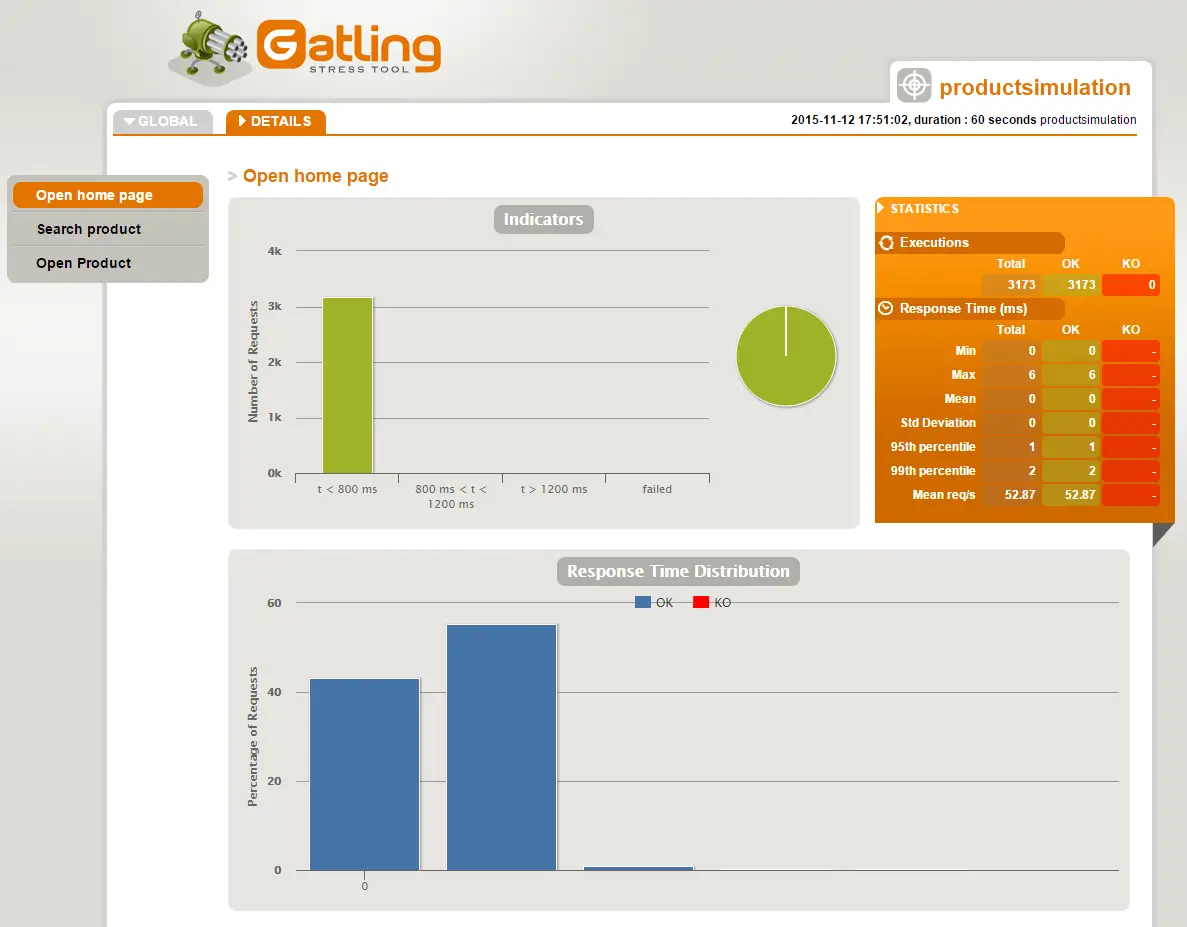
Post summary: Code samples and explanation how to do advanced performance testing with Gatling, such as proper scenarios structure, checks, feeding test data, session maintenance, etc.
Current post is part of Performance testing with Gatling series in which Gatling performance testing tool is explained in details.
Code samples are available in GitHub sample-performance-with-gatling repository.
In previous post Performance testing with Gatling – integration with Maven there is description how to setup Maven project. In Performance testing with Gatling – recorded simulation explanation there is information what a simulation consists of. Simulations from this post will be refactored in current post and more advanced topics will be discussed how to make flexible automation testing with Gatling.
What is included
Following topics are included in the current post:
- Access external configuration data
- Define single HTTP requests for better re-usability
- Add checks for content on HTTP response
- Check and extract data from HTTP response
- More checks and extract List with values
- Create HTTP POST request with the body from a template file
- Manage session variables
- Standard CSV feeder
- Create custom feeder
- Create unified scenarios
- Conditional scenario execution
- Only one HTTP protocol
- Extract data from HTTP request and response
- Advanced simulation setUp
- Virtual users vs requests per second
Refactored code
Below are all classes that are created after they have been refactored. In order to separate things and make it easier to read ProductSimulation and PersonSimulation classes contain only the setUp() method. Request, scenarios and external configurations are being defined into Constants, Product and Person singleton objects.
Constants
object Constants {
val numberOfUsers: Int = System.getProperty("numberOfUsers").toInt
val duration: FiniteDuration = System.getProperty("durationMinutes").toInt.minutes
val pause: FiniteDuration = System.getProperty("pauseBetweenRequestsMs").toInt.millisecond
val responseTimeMs = 500
val responseSuccessPercentage = 99
private val url: String = System.getProperty("url")
private val repeatTimes: Int = System.getProperty("numberOfRepetitions").toInt
private val successStatus: Int = 200
private val isDebug = System.getProperty("debug").toBoolean
val httpProtocol = http
.baseURL(url)
.check(status.is(successStatus))
.extraInfoExtractor { extraInfo => List(getExtraInfo(extraInfo)) }
def createScenario(name: String, feed: FeederBuilder[_], chains: ChainBuilder*): ScenarioBuilder = {
if (Constants.repeatTimes > 0) {
scenario(name).feed(feed).repeat(Constants.repeatTimes) {
exec(chains).pause(Constants.pause)
}
} else {
scenario(name).feed(feed).forever() {
exec(chains).pause(Constants.pause)
}
}
}
private def getExtraInfo(extraInfo: ExtraInfo): String = {
if (isDebug
|| extraInfo.response.statusCode.get != successStatus
|| extraInfo.status.eq(Status.apply("KO"))) {
",URL:" + extraInfo.request.getUrl +
" Request: " + extraInfo.request.getStringData +
" Response: " + extraInfo.response.body.string
} else {
""
}
}
}
Product
object Product {
private val reqGoToHome = exec(http("Open home page")
.get("/products")
.check(regex("Search: "))
)
private val reqSearchProduct = exec(http("Search product")
.get("/products?q=${search_term}&action=search-results")
.check(regex("Your search for '${search_term}' gave ([\\d]{1,2}) results:").saveAs("numberOfProducts"))
.check(regex("NotFound").optional.saveAs("not_found"))
)
private val reqOpenProduct = exec(session => {
var numberOfProducts = session("numberOfProducts").as[String].toInt
var productId = Random.nextInt(numberOfProducts) + 1
session.set("productId", productId)
}).exec(http("Open Product")
.get("/products?action=details&id=${productId}")
.check(regex("This is 'Product ${productId} name' details page."))
)
private val csvFeeder = csv("search_terms.csv").circular.random
val scnSearch = Constants.createScenario("Search", csvFeeder,
reqGoToHome, reqSearchProduct, reqGoToHome)
val scnSearchAndOpen = Constants.createScenario("Search and Open", csvFeeder,
reqGoToHome, reqSearchProduct, reqOpenProduct, reqGoToHome)
}
ProductSimulation
class ProductSimulation extends Simulation {
setUp(
Product.scnSearch.inject(rampUsers(Constants.numberOfUsers) over 10.seconds),
Product.scnSearchAndOpen.inject(atOnceUsers(Constants.numberOfUsers))
)
.protocols(Constants.httpProtocol.inferHtmlResources())
.pauses(constantPauses)
.maxDuration(Constants.duration)
.assertions(
global.responseTime.max.lessThan(Constants.responseTimeMs),
global.successfulRequests.percent.greaterThan(Constants.responseSuccessPercentage)
)
}
Person
object Person {
private val added = "Added"
private val updated = "Updated"
private val reqGetAll = exec(http("Get All Persons")
.get("/person/all")
.check(regex("\"firstName\":\"(.*?)\"").count.greaterThan(1).saveAs("count"))
.check(regex("\\[").count.is(1))
.check(regex("\"id\":([\\d]{1,6})").findAll.saveAs("person_ids"))
).exec(session => {
val count = session("count").as[Int]
val personIds = session("person_ids").as[List[Int]]
val personId = personIds(Random.nextInt(count)).toString.toInt
session.set("person_id", personId)
}).exec(session => {
println(session)
session
})
private val reqGetPerson = exec(http("Get Person")
.get("/person/get/${person_id}")
.check(regex("\"firstName\":\"(.*?)\"").count.is(1))
.check(regex("\\[").notExists)
)
private val reqSavePerson = exec(http("Save Person")
.post("/person/save")
.body(ElFileBody("person.json"))
.header("Content-Type", "application/json")
.check(regex("Person with id=([\\d]{1,6})").saveAs("person_id"))
.check(regex("\\[").notExists)
.check(regex("(" + added + "|" + updated + ") Person with id=").saveAs("action"))
)
private val reqGetPersonAferSave = exec(http("Get Person After Save")
.get("/person/get/${person_id}")
.check(regex("\"id\":${person_id}"))
.check(regex("\"firstName\":\"${first_name}\""))
.check(regex("\"lastName\":\"${last_name}\""))
.check(regex("\"email\":\"${email}\""))
)
private val reqGetPersonAferUpdate = exec(http("Get Person After Update")
.get("/person/get/${person_id}")
.check(regex("\"id\":${person_id}"))
)
private val uniqueIds: List[String] = Source
.fromInputStream(getClass.getResourceAsStream("/account_ids.txt"))
.getLines().toList
private val feedSearchTerms = Iterator.continually(buildFeeder(uniqueIds))
private def buildFeeder(dataList: List[String]): Map[String, Any] = {
Map(
"id" -> (Random.nextInt(100) + 1),
"first_name" -> Random.alphanumeric.take(5).mkString,
"last_name" -> Random.alphanumeric.take(5).mkString,
"email" -> Random.alphanumeric.take(5).mkString.concat("@na.na"),
"unique_id" -> dataList(Random.nextInt(dataList.size))
)
}
val scnGet = Constants.createScenario("Get all then one", feedSearchTerms,
reqGetAll, reqGetPerson)
val scnSaveAndGet = Constants.createScenario("Save and get", feedSearchTerms, reqSavePerson)
.doIfEqualsOrElse("${action}", added) {
reqGetPersonAferSave
} {
reqGetPersonAferUpdate
}
}
PersonSimulation
class PersonSimulation extends Simulation {
setUp(
Person.scnGet.inject(atOnceUsers(Constants.numberOfUsers)),
Person.scnSaveAndGet.inject(atOnceUsers(Constants.numberOfUsers))
)
.protocols(Constants.httpProtocol)
.pauses(constantPauses)
.maxDuration(Constants.duration)
.assertions(
global.responseTime.max.lessThan(Constants.responseTimeMs),
global.successfulRequests.percent.greaterThan(Constants.responseSuccessPercentage)
)
}
Access external configuration data
In order to have flexibility it is mandatory to be able to sent different configurations parameters from command line when invoking the scenario. With Gatling Maven plugin it is done with configurations. See more in Performance testing with Gatling – integration with Maven post.
val numberOfUsers: Int = System.getProperty("numberOfUsers").toInt
val duration: FiniteDuration = System.getProperty("durationMinutes").toInt.minutes
private val url: String = System.getProperty("url")
private val repeatTimes: Int = System.getProperty("numberOfRepetitions").toInt
private val isDebug = System.getProperty("debug").toBoolean
Define single HTTP requests for better re-usability
It is a good idea to define each HTTP request as a separate object. This gives the flexibility to reuse one and the same requests in different scenarios. Below is shown how to create HTTP GET request with http().get().
Add checks for content on HTTP response
On HTTP request creation there is a possibility to add checks that certain string or regular expression pattern exists in response. The code below created HTTP Request and add check that “Search: “ text exists in response. This is done with regex() method by passing just a string to it.
private val reqGoToHome = exec(http("Open home page")
.get("/products")
.check(regex("Search: "))
)
Check and extract data from HTTP response
It is possible along with the check to extract data into a variable that is being saved to the session. This is done with saveAs() method. In some cases value we are searching for, might not be in the response. We can use optional method to specify that value is saved in session only if existing. If it is not existing it won’t be captured and this will not break the execution. As shown below session variables can be also used in the checks. Session variable is accessed with ${}, such as ${search_term}.
private val reqSearchProduct = exec(http("Search product")
.get("/products?q=${search_term}&action=search-results")
.check(regex("Your search for '${search_term}' gave ([\\d]{1,2}) results:")
.saveAs("numberOfProducts"))
.check(regex("NotFound").optional.saveAs("not_found"))
)
More checks and extract List with values
There are many types of checks. In code below count.greaterThan(1) and count.is(1) are used. It is possible to search for multiple occurrences of given regular expression with findAll. In such case saveAs() saves the results to a “person_ids” List object in session. More information about checks can be found in Gatling Checks page.
private val reqGetAll = exec(http("Get All Persons")
.get("/person/all")
.check(regex("\"firstName\":\"(.*?)\"").count.greaterThan(1).saveAs("count"))
.check(regex("\\[").count.is(1))
.check(regex("\"id\":([\\d]{1,6})").findAll.saveAs("person_ids"))
)
Create HTTP POST request with the body from a template file
If you need to post data to server HTTP POST request is to be used. The request is created with http().post() method. Headers can be added to the request with header() or headers() methods. In the current example, without Content-Type=application/json header REST service will throw an error for unrecognized content. Data that will be sent is added in body() method. It accepts Body object. You can generate body from a file (RawFileBody method) or string (StringBody method).
private val reqSavePerson = exec(http("Save Person")
.post("/person/save")
.body(ElFileBody("person.json"))
.header("Content-Type", "application/json")
.check(regex("Person with id=([\\d]{1,6})").saveAs("person_id"))
.check(regex("\\[").notExists)
.check(regex("(" + added + "|" + updated + ") Person with id=")
.saveAs("action"))
)
In current case body is generated from file, which have variables that can be later on found in session. This is done with ElFileBody (ELFileBody in 2.0.0) method and actual replace with value is done by Gatling EL (expression language). More about what can you do with EL can be found on Gatling EL page. EL body file is shown below, where variables ${id}, ${first_name}, ${last_name} ${email} are searched in session and replaced if found. If not found error is shown on scenario execution output.
{
"id": "${id}",
"firstName": "${first_name}",
"lastName": "${last_name}",
"email": "${email}"
}
Manage session variables
Each virtual user has its own session. The scenario can store or read data from the session. Data is saved in session with key/value pairs, where the key is the variable name. Variables are stored in session in three ways: using feeders (this is explained later in the current post), using saveAs() method and session API. More details on session API can be found in Gatling Session API page.
Manipulating session through API is kind of tricky. Gatling documentation is vague about it. Below is shown a code where session variable is extracted first as String and then converted to Int with: var numberOfProducts = session(“numberOfProducts”).as[String].toInt. On next step some manipulation is done with this variable, in current case, a random product id from 1 to “numberOfProducts” to is picked. At last a new variable is saved in session with session.set(“productId”, productId). It is important that this is the last line of session manipulation code block done in first exec(). This is the return statement of the code block. In other words, new Session object with saved “productId” in it is returned. If on the last line is just “session” as stated in the docs, then old, an unmodified session object is returned without variable being added.
Sessions as most of the objects in Gatling and in Scala are immutable. This is designed for thread safety. So adding a variable to session actually creates a new object. This is why newly added session variable cannot be used in the same exec() block, but have to be used on next one, as in same block variable is yet not accessible. See code below in the second exec() “productId” is already available and can be used in get().
private val reqOpenProduct = exec(session => {
var numberOfProducts = session("numberOfProducts").as[String].toInt
var productId = Random.nextInt(numberOfProducts) + 1
session.set("productId", productId)
}).exec(http("Open Product")
.get("/products?action=details&id=${productId}")
.check(regex("This is 'Product ${productId} name' details page."))
)
Same logic being explained above is implemented in next code fragment. The below example shows usage of session variable saved in previous exec() fragment. Count of persons and List with ids are being saved by saveAs() method. The list is extracted from the session and random index of it has been accessed, so random person is being selected. This is again saved into session as “person_id”. In third exec() statement “session” object is just printed to output for debugging purposes.
private val reqGetAll = exec(http("Get All Persons")
.get("/person/all")
.check(regex("\"firstName\":\"(.*?)\"").count.greaterThan(1).saveAs("count"))
.check(regex("\\[").count.is(1))
.check(regex("\"id\":([\\d]{1,6})").findAll.saveAs("person_ids"))
).exec(session => {
val count = session("count").as[Int]
val personIds = session("person_ids").as[List[Int]]
val personId = personIds(Random.nextInt(count)).toString.toInt
session.set("person_id", personId)
}).exec(session => {
println(session)
session
})
Standard CSV feeder
A feeder is a way to generate unique data for each virtual user. This how tests are made real. Below is a way to read data from CSV file. The first line of the CSV file is the header which is saved to the session as a variable name. In the current example, CSV has only one column, but it is possible to have CSV file with several columns. circular means that if file end is reached feeder will start from the beginning. random means elements are taken in random order. More about feeders can be found in Gatling Feeders page.
private val csvFeeder = csv("search_terms.csv").circular.random
Create custom feeder
Feeder actually is Iterator[Map[String, T]], so you can do your own feeders. Below is shown code where some unique ids are read from file and converted to List[String] with Source .fromInputStream(getClass.getResourceAsStream(“/account_ids.txt”)) .getLines().toList. This list is used in buildFeeder() method to access random element from it. Finally Iterator.continually(buildFeeder(uniqueIds)) creates infinite length iterator.
private val uniqueIds: List[String] = Source
.fromInputStream(getClass.getResourceAsStream("/account_ids.txt"))
.getLines().toList
private val feedSearchTerms = Iterator.continually(buildFeeder(uniqueIds))
private def buildFeeder(dataList: List[String]): Map[String, Any] = {
Map(
"id" -> (Random.nextInt(100) + 1),
"first_name" -> Random.alphanumeric.take(5).mkString,
"last_name" -> Random.alphanumeric.take(5).mkString,
"email" -> Random.alphanumeric.take(5).mkString.concat("@na.na"),
"unique_id" -> dataList(Random.nextInt(dataList.size))
)
}
The current business case doesn’t make much sense to have a custom feeder with values from a file, just Map() generator is enough. But let us imagine a case where you search for a hotel by unique id and some date in the future. Hard coding date in CSV file is not a wise solution, you will want to be always in the future. Also making different combinations from hotelId, start and end dates is not possible to be maintained in a file. The best solution is to have a file with hotel ids and dates to be dynamically generated as shown in buildFeeder() method.
Create unified scenarios
The scenario is created from HTTP requests. This is why it is good to have each HTTP request as a separate object so you can reuse them in different scenarios. In order to unify scenario creation, there is a special method. It takes scenario name, feeder and list of requests and returns a scenario object. Method checks if the scenario is supposed to be repeated several times and uses repeat() method. Else scenarios are repeated forever(). In both cases, there is constant pause time introduced between requests with pause().
def createScenario(name: String,
feed: FeederBuilder[_],
chains: ChainBuilder*): ScenarioBuilder = {
if (Constants.repeatTimes > 0) {
scenario(name).feed(feed).repeat(Constants.repeatTimes) {
exec(chains).pause(Constants.pause)
}
} else {
scenario(name).feed(feed).forever() {
exec(chains).pause(Constants.pause)
}
}
}
With this approach, a method can be reused from many places avoiding duplication of code.
val scnSearch = Constants.createScenario("Search", csvFeeder,
reqGoToHome, reqSearchProduct, reqGoToHome)
Conditional scenario execution
It is possible one scenario to have different execution paths based on a condition. This condition is generally a value of a session variable. Branching is done with doIf, doIfElse, doIfEqualsOrElse, etc methods. In the current example, if this is Save request then additional reqGetPersonAferSave HTTP request is executed. Else additional reqGetPersonAferUpdate HTTP request is executed. In the end, there is only one scenario scnSaveAndGet but it can have different execution paths based on “action” session variable.
val scnSaveAndGet = Constants
.createScenario("Save and get", feedSearchTerms, reqSavePerson)
.doIfEqualsOrElse("${action}", added) {
reqGetPersonAferSave
} {
reqGetPersonAferUpdate
}
Only one HTTP protocol
In general case, several performance testing simulations can be done for one and the same application. During simulation setUp an HTTP protocol object is needed. Since the application is the same HTTP protocol can be one and the same object, so it is possible to define it and reuse it. If changes are needed new HTTP protocol object can be defined or a copy of current one can be created and modified.
val httpProtocol = http
.baseURL(url)
.check(status.is(successStatus))
.extraInfoExtractor { extraInfo => List(getExtraInfo(extraInfo)) }
Extract data from HTTP request and response
In order to ease debugging of failures or debugging at all, it is possible to extract information from HTTP request and response. Extraction is configured on HTTP protocol level with extraInfoExtractor { extraInfo => List(getExtraInfo(extraInfo)) } as shown above. In order to simplify code processing of extra info object is done in a separate method. If debug is enabled or response code is not 200 or Gatling status is KO then request URL, request data and response body are dumped into simulation.log file that resides in results folder. Note that response body is extracted only if there is check on it, otherwise, there is NoResponseBody in the output. This is done to improve performance.
private def getExtraInfo(extraInfo: ExtraInfo): String = {
if (isDebug
|| extraInfo.response.statusCode.get != successStatus
|| extraInfo.status.eq(Status.apply("KO"))) {
",URL:" + extraInfo.request.getUrl +
" Request: " + extraInfo.request.getStringData +
" Response: " + extraInfo.response.body.string
} else {
""
}
}
Advanced simulation setUp
It is a good idea to keep simulation class clean by defining all objects in external classes or singleton objects. Simulation is mandatory to have setUp() method. It receives a comma-separated list of scenarios. In order scenario to be valid, it should have users injected with inject() method. There are different strategies to inject users. The protocol should also be defined per scenario setup. In this particular example default protocol is used with the change to fetch all HTTP resources on a page (JS, CSS, images, etc.) with inferHtmlResources(). Since objects are immutable this creates a copy of default HTTP protocol and does not modify the original one. Assertions is a way to verify certain performance KPI it is defined with assertions() method. In this example, we should have a response time less than 500ms and more than 99% of requests should be successful.
private val rampUpTime: FiniteDuration = 10.seconds
setUp(
Product.scnSearch.inject(rampUsers(Constants.numberOfUsers) over rampUpTime),
Product.scnSearchAndOpen.inject(atOnceUsers(Constants.numberOfUsers))
)
.protocols(Constants.httpProtocol.inferHtmlResources())
.pauses(constantPauses)
.maxDuration(Constants.duration)
.assertions(
global.responseTime.max.lessThan(Constants.responseTimeMs),
global.successfulRequests.percent
.greaterThan(Constants.responseSuccessPercentage)
)
.throttle(reachRps(100) in rampUpTime, holdFor(Constants.duration))
Cookies management
Cookie support is enabled by default and then Gatling handles Cookies transparently, just like a browser would. It is possible to add or delete cookies during the simulation run. See more details how this is done in Gatling Cookie management page.
Virtual users vs requests per second
Since users are vague metric, but requests per second is metric that most server monitoring tools support it is possible to use this approach. Gatling supports so-called throttling: throttle(reachRps(100) in 10.seconds, holdFor(5.minutes)). It is important to put holdFor() method, otherwise, Gatling goes to unlimited requests per second and can crash the server. More details on simulation setup can be found on Gatling Simulation setup page.
Conclusion
Keeping Gatling code maintainable and reusable is a good practice to create complex performance scenarios. Gatling API provides a wide range of functionalities to support this task. In the current post, I have shown cases and solution to them which I have encountered in real life projects.
Related Posts